ATS and PDFs
Why Simple PDFs Beat Pretty Resumes (An ATS Experiment)
While working on a project, I noticed something interesting:
the simpler a PDF is, the easier it is to extract data from it.
That instantly made me think about resumes — and why mine wasn’t getting shortlisted as often as I expected.
Note: I don’t actually know how ATS systems work internally, and I never really believed in them.
But if they do exist, this is probably close to how they work.
So I tried to replicate an ATS-like flow.
Step 1: Extract the text
I started by extracting all the text from a resume PDF.
Step 2: Normalize it
Using Python libraries, I normalized the text:
- removed extra spaces
- stripped punctuation
- fixed weird formatting and characters
Basically, I tried to reduce the PDF to clean, machine-readable text.
Step 3: Split it into words
Next, I split the entire text into individual words.
At this point, the resume was just a big list of tokens.
But… what does an ATS actually want?
Skills.
That’s it.
So I moved to the next step.
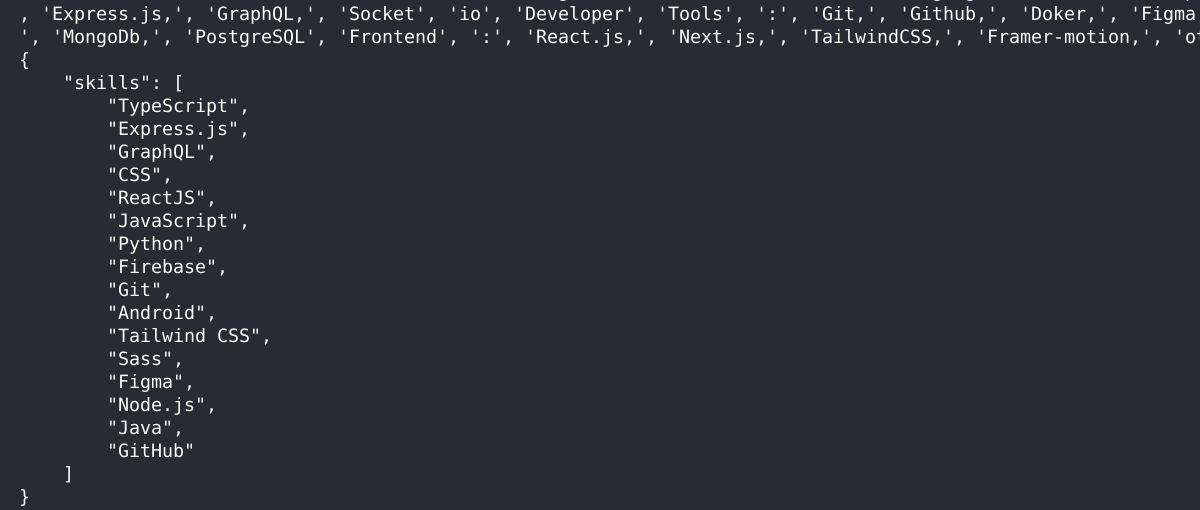
Step 4: Skill matching
To extract skills from a resume:
- I created a large JSON file containing known skills scraped from the internet
- I checked every word from the resume against this skills list
And… damn, it worked.
The interesting part
While testing further, I noticed something subtle but important.
In my resume, I had written “socket io” instead of “socket.io”.
When the text was split, it became:
socketio
Neither of these matched socket.io in the skills JSON.
So as far as the system was concerned,
I didn’t know Socket.IO.
I tested this approach on multiple resumes, and the results were surprisingly consistent.
The conclusion
If you’re applying for jobs through portals, keep your resume boring:
- simple formatting
- standard fonts
- black & white
- no fancy layouts or graphics
These parse far more reliably.
And if you want to get fancy?
Keep a separate aesthetic resume for cold DMs or direct emails — because humans like pretty stuff.
Machines don’t.